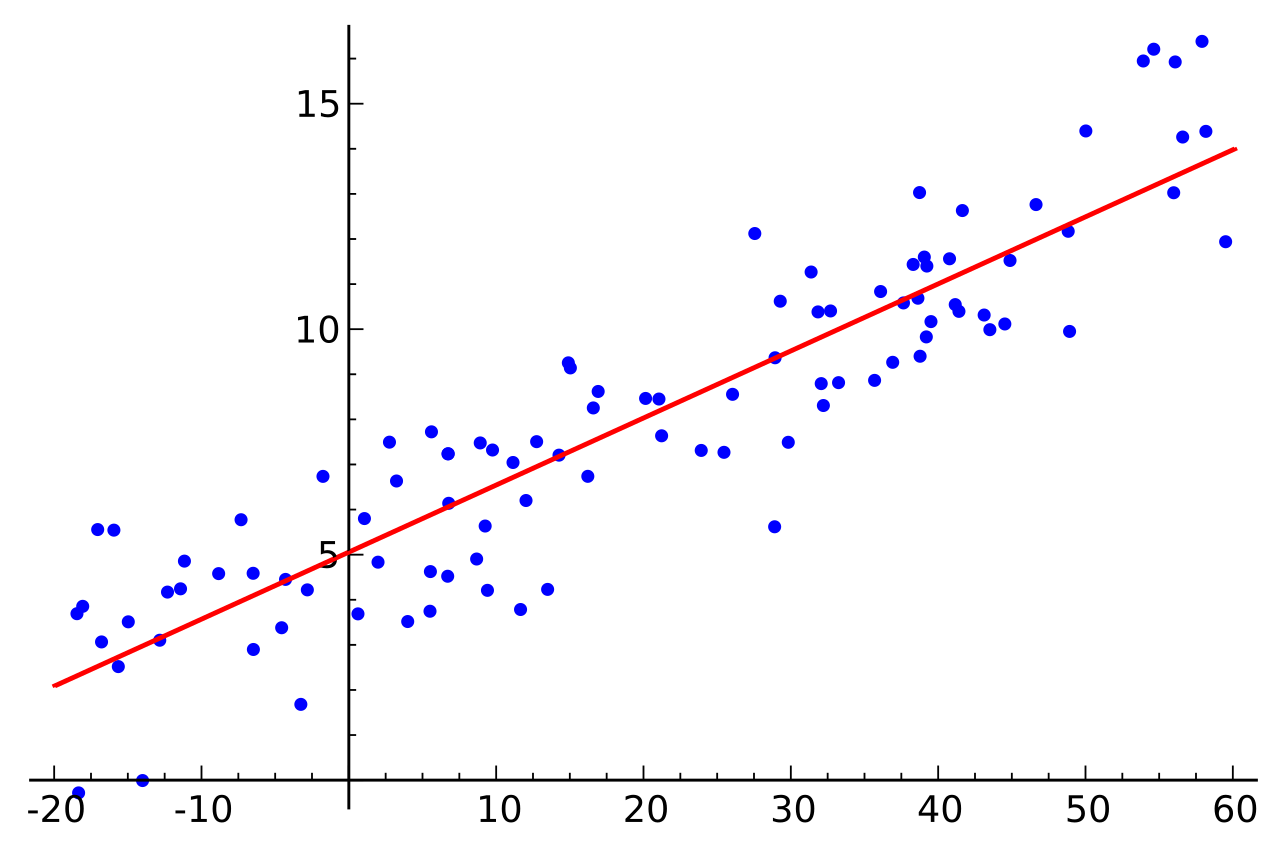
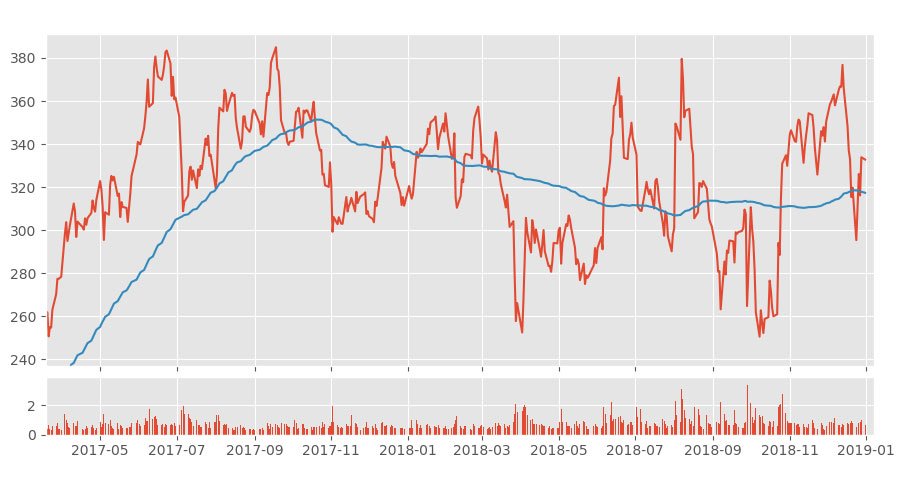
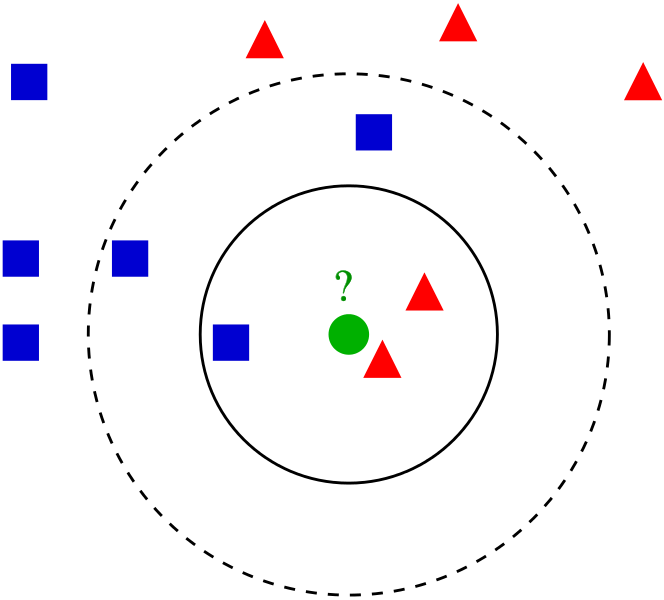
K Nearest Neighbors is a popular classification algorithm for supervised machine learning. It permits to divide data points into groups, defining a model that will then be able to classify an unknown data point in one group or another. The K parameter, defined during programming, allows the algorithm to classify unknown data points by examining the K closest known data points.
 Continue reading “How to program the K Nearest Neighbors algorithm”
Continue reading “How to program the K Nearest Neighbors algorithm”