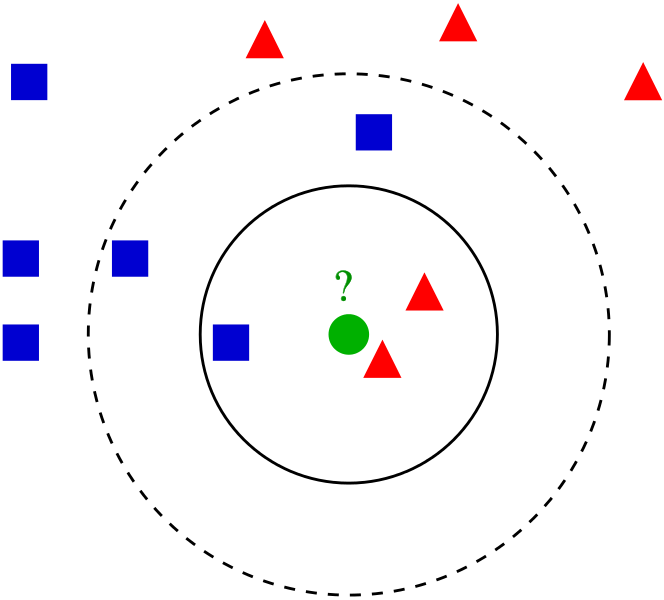
K Nearest Neighbors is a popular classification algorithm for supervised machine learning. It permits to divide data points into groups, defining a model that will then be able to classify an unknown data point in one group or another. The K parameter, defined during programming, allows the algorithm to classify unknown data points by examining the K closest known data points.
To go into the details of K nearest neighbors – often abbreviated KNN – and to program it in Python, this complete series of tutorials by Harrison Kinsley, a.k.a. Sentdex, dives in all the details of the K nearest neighbors classifier, programming tricks and present example uses of the algorithm.
The following videos regroup the K Nearest Neighbors tutorials from the Machine Learning with Python series (parts 13 to 19) by Sentdex on Youtube. The final code can also be obtained from Sentdex Python Programming website, in the corresponding K nearest neighbors tutorial with more examples, details on the code and links to other key concepts and Python functions.
Note that the K nearest neighbors algorithm works with any number of data groups, but the K parameter needs to be chosen so as to avoid the indecision of whether a data point belongs to a group or another, usually by picking an odd number that takes into account the number of groups. For a complete presentation of this classifier, with mathematical formulas and extensions, check the Wikipedia page on the K nearest neighbors algorithm.
To go further in each tutorial video, check the comments of the video on Youtube and the corresponding tutorial on the PythonProgramming website.
import numpy as np
from math import sqrt
import warnings
from collections import Counter
import pandas as pd
import random
def k_nearest_neighbors(data, predict, k=3):
if len(data) >= k:
warnings.warn('K is set to a value less than total voting groups!')
distances = []
for group in data:
for features in data[group]:
euclidean_distance = np.linalg.norm(np.array(features)-np.array(predict))
distances.append([euclidean_distance, group])
votes = [i[1] for i in sorted(distances)[:k]]
vote_result = Counter(votes).most_common(1)[0][0]
confidence = Counter(votes).most_common(1)[0][1] / k
return vote_result, confidence
df = pd.read_csv("breast-cancer-wisconsin.data.txt")
df.replace('?',-99999, inplace=True)
df.drop(['id'], 1, inplace=True)
full_data = df.astype(float).values.tolist()
random.shuffle(full_data)
test_size = 0.4
train_set = {2:[], 4:[]}
test_set = {2:[], 4:[]}
train_data = full_data[:-int(test_size*len(full_data))]
test_data = full_data[-int(test_size*len(full_data)):]
for i in train_data:
train_set[i[-1]].append(i[:-1])
for i in test_data:
test_set[i[-1]].append(i[:-1])
correct = 0
total = 0
for group in test_set:
for data in test_set[group]:
vote,confidence = k_nearest_neighbors(train_set, data, k=5)
if group == vote:
correct += 1
total += 1
print('Accuracy:', correct/total)