Reinforcement Learning is one of the most exciting parts of Machine Learning and AI, as it allows for the programming of agents taking decisions in both virtual and real-life environments. This MIT course presents the theoretical background as well as the actual Deep Q-Network algorithm, that power some of the best Reinforcement Learning applications.

The following video is a MIT course by Lex Fridman, detailing the theoretical approach to Reinforcement Learning and Deep Reinforcement Learning. He details the inner workings of Q-Learning and Deep Q-Learning, and why neural networks make a big difference in the latest Reinforcement Learning architectures.
Principles of Reinforcement Learning
Reinforcement Learning explores the problem of how to teach systems to perceive the world and act from data.
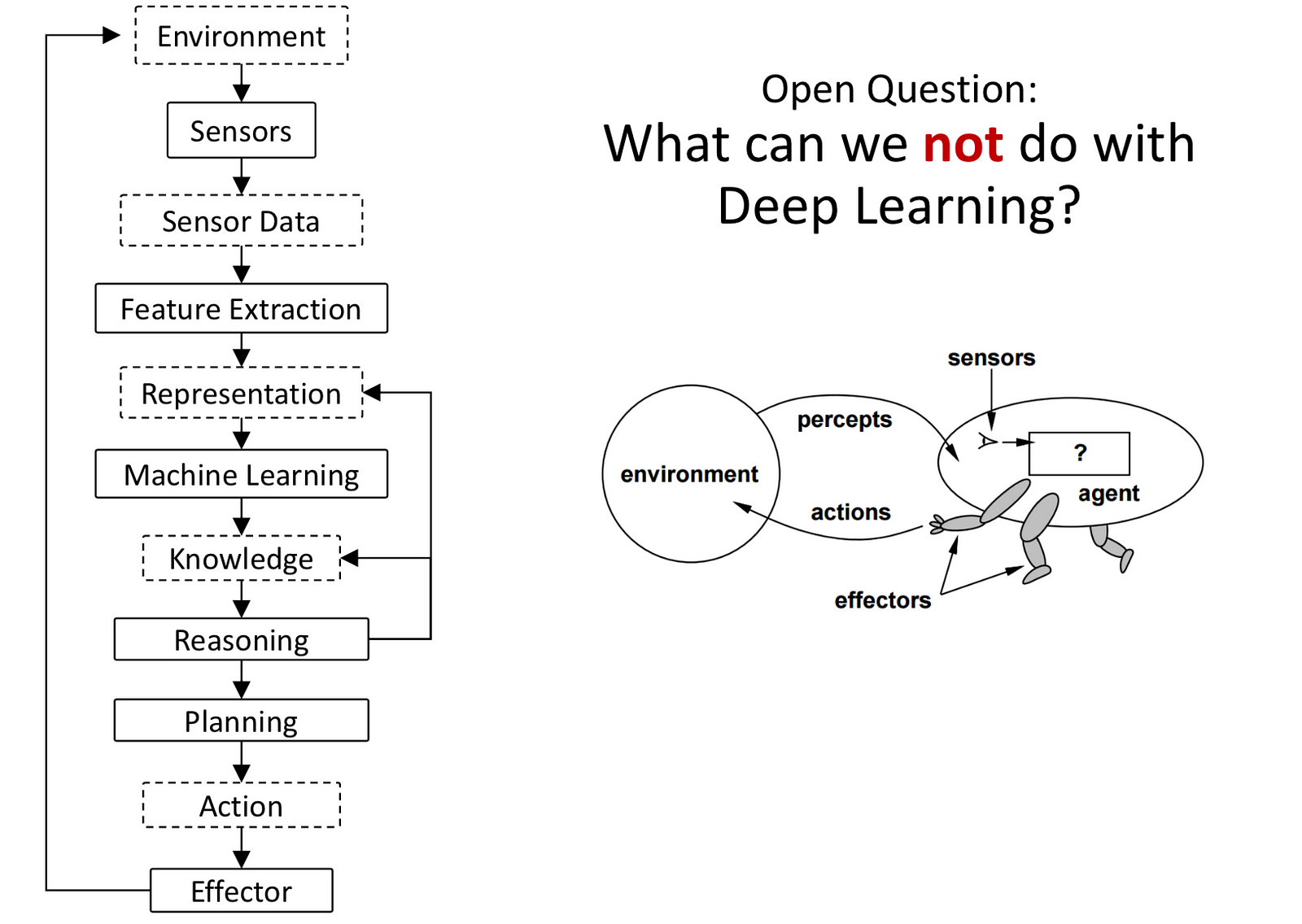
Here are the types of tasks that can be managed by Deep Reinforcement Learning approaches:
- Formal tasks: playing games, solving puzzles, math and logic problems
- Expert tasks: medical diagnosis, engineering, scheduling, computer hardware design
- Mundane tasks: speech and language, perception, walking, object manipulation
- Human tasks: awareness of self, emotion, imagination, morality, subjective experience, high-level reasoning, consciousness
Reinforcement Learning is a form of semi-supervised learning where only some input is provided by humans, some ground truths, while the rest must be inferred and generalized by the system from sparse reward data. It assumes that there is a temporal consistency from state to state through time, and that information can be propagated to infer some predictions.

Major components of a Reinforcement Learning Agent
- Policy: agent’s behavior function
- Value function: how good is each state and/or action
- Model: agent’s representation of the environment
The goal of the policy is to have an optimal action to take in every single step.
The value function measures the reward that is likely to be received in the future. To anticipate the reward that is likely to be received, the future rewards are discounted as they are not always certain to be obtained. A parameter γ is therefore added to future rewards to discount them more and more for each future step. A good strategy is therefore to maximize the sum of future discounted rewards.
Q-learning
Q-learning is a method that does not take into account any policy, but approximates future rewards through the Bellman equation, by estimating how good an action (a) is in a certain state (s), through the Q function. The higher the learning rate the more value is assigned to new information (reducing the discount factor).
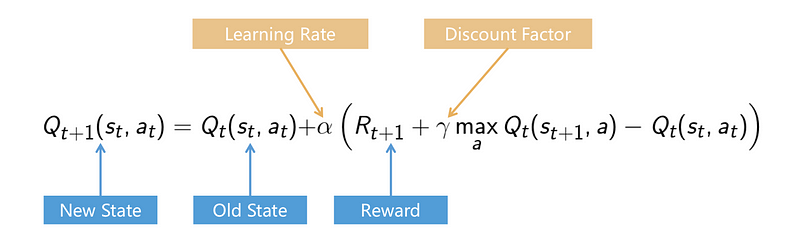
Q-learning is particularly interesting for the exploration of an environment and learning what is the best action to take in it. Even though the learning process improves the Q function and the exploitation of the environment, the Q function remains an approximation, therefore it must be mitigated with the need for exploration of the environment. Thus the value of exploration is often greater at the beginning of training, allowing the system to get a broader sense of its environment.
As the system learns over time, the approximation develops a Q table of optimal actions for each segment of the space. A problem arises when the Q table is exponential in size making the Bellman equation computationally impractical. So Deep Learning can then be used to accurately approximate the learning of this Q table with Neural Networks, giving purpose to Deep Reinforcement Learning.
Deep Reinforcement Learning
Deep Learning allows to propagate the outcomes of states and actions of Reinforcement Learning into much larger action spaces, thanks to the capacity of generalization of neural networks. Deep Reinforcement Learning therefore helps to represent an environment.
Deep Q-learning
Instead of assessing each state and action, a neural network is used, with the space as input, and the different values of Q (reward) that can be obtained from it as its output. The neural network is trained by gradient descent to reduce a loss function obtained from the Bellman equation.

Developed by DeepMind to play games in 2013, the Deep Q-Network was actually greatly improved through some programming tricks. A major trick was “experience replay“: collecting experiences of playing the game multiple times and sampling the library of past games to implement the best actions.
Other tricks that helped included “fixed target network“, the update of the network only every 1000 iterations so as to increase the stability of the training process, as well as clipping rewards to 1 and -1 to normalize the reward structure, and skipping frames as actions are not needed at every step.
Deep Q-learning Algorithm

AlphaGo Zero
AlphaGo was developed by DeepMind to play the game of Go. In 2016 it successfully beat the world champion of Go, Lee Sedol, 4 games to 1. It worked by playing against human players and collecting data on the best moves and strategies to play.

AlphaGo Zero, was an improvement on AlphaGo in the fact that it was not trained by playing against humans but by only playing against itself.
As many Go-playing computers, it works through Monte-Carlo Tree Search, balancing exploitation and exploration of the game to choose the best move, by going deep in the exploitation of promising positions, or exploring new underplayed positions.
However, in AlphaGo Zero the addition of a neural network allowed to assess the best positions to explore. This neural net outputs the probability of what move to take and what the probability of winning is.
Deep Traffic challenge
The MIT class is given a challenge to improve traffic conditions in the US. If you’re interested in the challenge, training and testing your code, go to the challenge site.