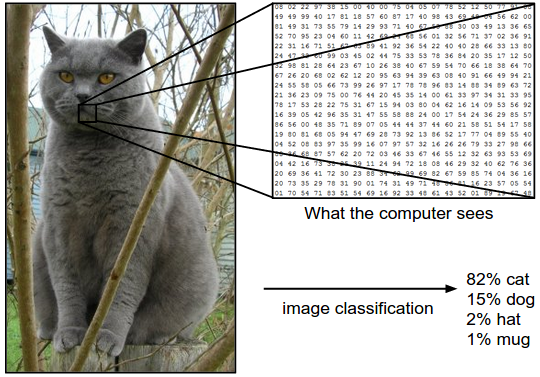
Computer vision is a key aspect of artificial intelligence that is critical to many applications, from robots movements to self-driving cars and from medical imaging to products recognition in manufacturing plants. This MIT course presents the issues of computer vision and how they are handled with Convolutional Neural Networks together with the latest domains of research and state-of-the-art algorithms architectures.
Machine learning makes use of multiple mathematical formulas and relations to implement the different tasks it can handle. Gathered in the following “cheat sheets” by Afshine and Shervine Amidi, the concepts for supervised and unsupervised learning, deep learning together with machine learning tips and tricks, probabilities, statistics algebra and calculus reminders, are all presented in details with the underlying math.
Based on the Stanford course on Machine Learning (CS 229), the cheat sheets summarize the important concepts of each branch with simple explanations and diagrams, such as the following table cover underfitting and overfitting.
Underfitting
Just right
Overfitting
Symptoms
• High training error • Training error close to test error • High bias
• Training error slightly lower than test error
• Very low training error • Training error much lower than test error • High variance
Regression illustration
Classification illustration
Deep learning illustration
Possible remedies
• Complexify model • Add more features • Train longer
• Perform regularization • Get more data
The main machine learning cheat sheets can be found here:
Supervised Learning Results about linear models, generative learning, support vector machines and kernel methods
Unsupervised Learning Formulas about clustering methods and dimensionality reduction
Deep Learning Main concepts around neural networks, backpropagation and reinforcement learning
This series of articles dives deeper into the actual applications of Machine Learning that are currently in use in many current technological processes and devices.
Through these posts entitled “Machine Learning is Fun!”, Adam Geitgey guides us step by step through the concepts, data, algorithms, code, results and pitfalls of machine learning applications from image, face and speech recognition to language translation and more. It also gathers several different sources for more details on each application and its development.
This series is really dense with detailed code, but it is also explained very clearly, step by step, with detailed illustration. It notably covers the use of a Convolutional Neural Network (including Generative Adversarial Network) and Recurrent Neural Network, together with some of their most prominent applications in daily life. It is a real course not to be missed for any ML developer!
Neural networks come in a wide range of shapes and functions, with diverse architectures and parameters for input, hidden and output nodes as well as convolutive or recurrent nodes.
Overview of the most popular neural networks
Regrouped in a convenient summary by Fjodor Van Veen, the most popular architectures for neural networks have been cataloged with detailed descriptions for each type of neural network. The complete post with explanations on the use and goals of each network can be be found on the Asimov Institute “the neural network zoo“.
TensorFlow is an open-source machine learning framework developed by Google. It relies upon Tensors (multi-dimensional arrays) which empower a wide range of API to develop machine learning applications, primarily deep neural networks. TensorFlow is commonly used in machine learning practice, so better start using it already.
Thankfully the TensorFlow website provides a guide for programmers as well as detailed tutorials. Here is the basic tutorial to get get started with TensorFlow. To accompany programmers, Google cloud has also created a series of videos on machine learning and TensorFlow.
This next video is going over the basic tutorial with iris flowers images classification. Yufeng Guo walks us through the initial tutorial to develop a linear model to classify flowers, corresponding to the explanations and code available in the page “getting started with TensorFlow: Premade Estimators” and aimed at readers who have some experience in machine learning.
Note: to get this tutorial running well, you will need to have a Python IDE (such as PyCharm, or a Jupyter notebook) with a virtual environment loaded with the TensorFlow, Pandas and Numpy librairies. You will also need a Git client software (Git for Windows if you’re using Windows) to download the data from GitHub. You may use Anaconda to properly load the librairies in your Python IDE.