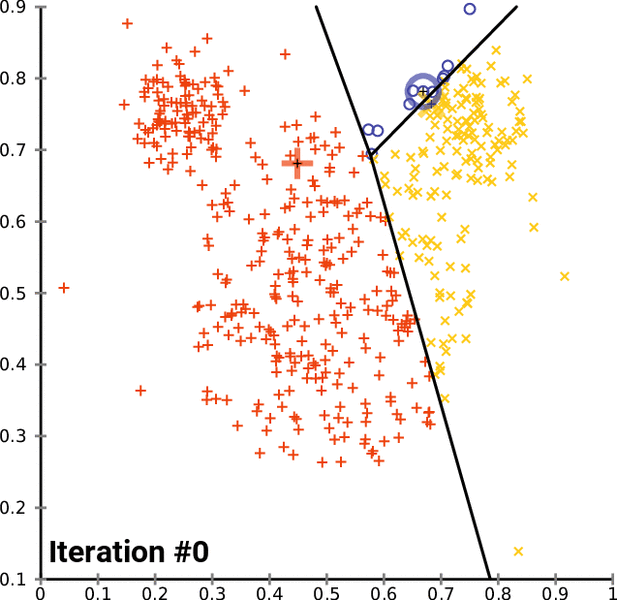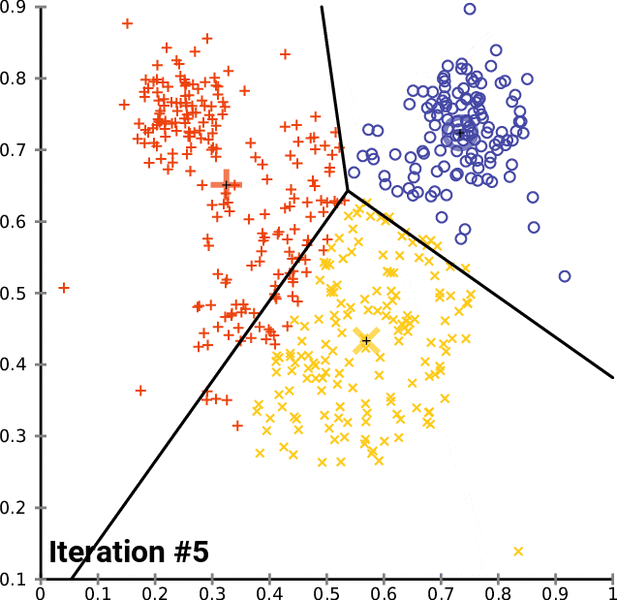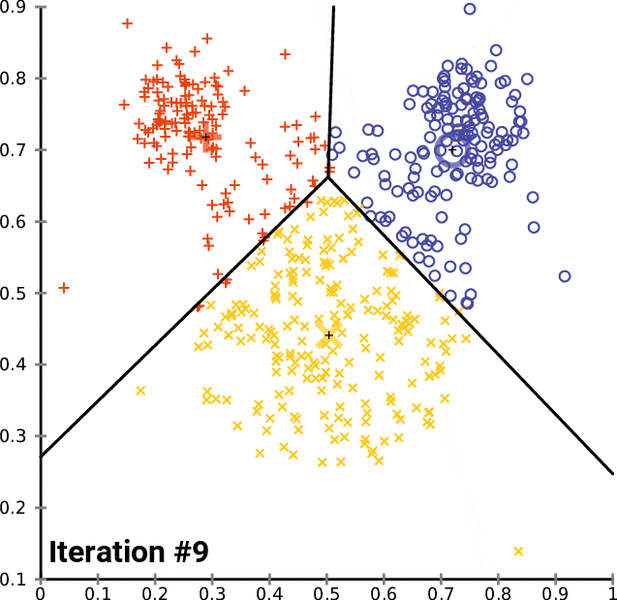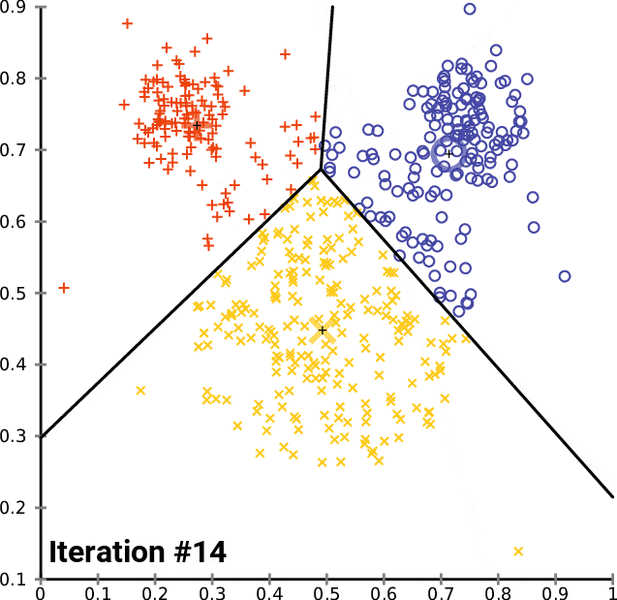
A key element of Artificial Intelligence, Natural Language Processing is the manipulation of textual data through a machine in order to “understand” it, that is to say, analyze it to obtain insights and/or generate new text. In Python, this is most commonly done with NLTK.
 Continue reading “Basics of Natural Language Processing with NLTK”
Continue reading “Basics of Natural Language Processing with NLTK”