Working with images can be a very time-consuming task, especially if you have many images to work on. Machine learning can thus be a great time-saver for various image analysis and editing tasks, such as finding the dominant colors of an image thanks to the K-means clustering algorithm.
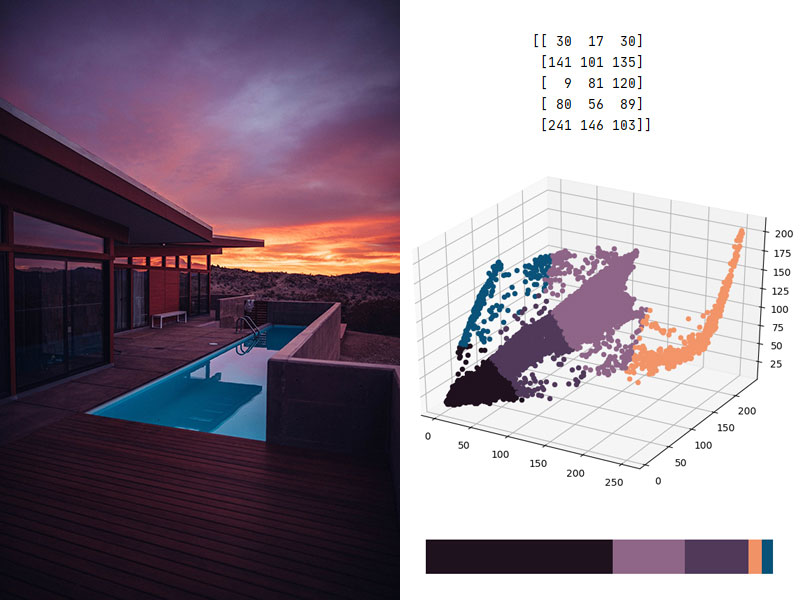
The K-means clustering algorithm defines a number K of clusters and the best “centroids” to cluster the data around. When applied to images, it allows extracting the k dominant colors in an image to be used for other purposes.
Thankfully, all the programming has already been done by Shivam K Thakkar, you just need to follow his post and everything works like a charm, allowing to extract as few or as many dominant colors from any image. The Python code relies on OpenCV, Scikit-Learn, Numpy, and Matplotlib for visualization, which must, therefore, be installed first.
However, Shivam’s code is built to extract colors from a small image and tends to be slow for larger images. If you are interested in using it for larger images, just use the code below which first reduces the size of images, vastly reducing the computing time.
Just modify the scale_percent = 10 parameter to make sure the size of the reduced images is large enough to extract proper colors and small enough to remain in reasonable computing time.