AI-Powered Go-To-Market Outreach Drafting Platform
- Service: Custom AI Application Development
- Timeline: 1 month (design through delivery)
- Stack: Python, Django, Celery, OpenAI API, PostgreSQL
- Channels: Email, LinkedIn, X (Twitter)
The Problem
Our client, a B2B SaaS founder running lean, was doing outbound sales across Email, LinkedIn, and X entirely by hand. The workflow looked like this: export a lead list, open ChatGPT, paste context, write a message, copy it into LinkedIn, repeat. For every lead. On every channel. At every follow-up step.
Three pain points made this unsustainable:
- Speed. Crafting a genuinely personalized message took 5 to 10 minutes per lead. At 50 leads per week across multiple channels, outbound was consuming entire workdays.
- Quality control. LLM-generated messages regularly hallucinated facts about leads, referencing blog posts they never wrote, funding rounds that never happened. Every draft needed line-by-line review to avoid embarrassment.
- Operational chaos. There was no single system tracking who had been contacted, on which channel, at which sequence step, or when follow-ups were due. Leads fell through the cracks. Conversations went cold.
The client needed a system that could generate high-quality, multi-channel outreach drafts from real lead data, with guardrails that prevented hallucination, while also serving as the operational hub for managing the entire outbound pipeline.
The Solution
We designed and built Outbound Engine: a full-stack AI application that transforms raw lead data into channel-ready outreach drafts, enforces strict compliance rules, and provides a command center for managing the complete outreach lifecycle.
Architecture Overview
Outbound Engine is a Django application with Celery for async task processing and the OpenAI API for LLM-powered draft generation. The system is organized around five core modules:
- Product Playbooks – structured configurations (factsheets, personas, guardrails, sequence templates, knowledge base) that keep every generated message on-brand and policy-compliant.
- Lead Management – CSV import with field mapping, normalization, deduplication, suppression lists, and per-lead scoring.
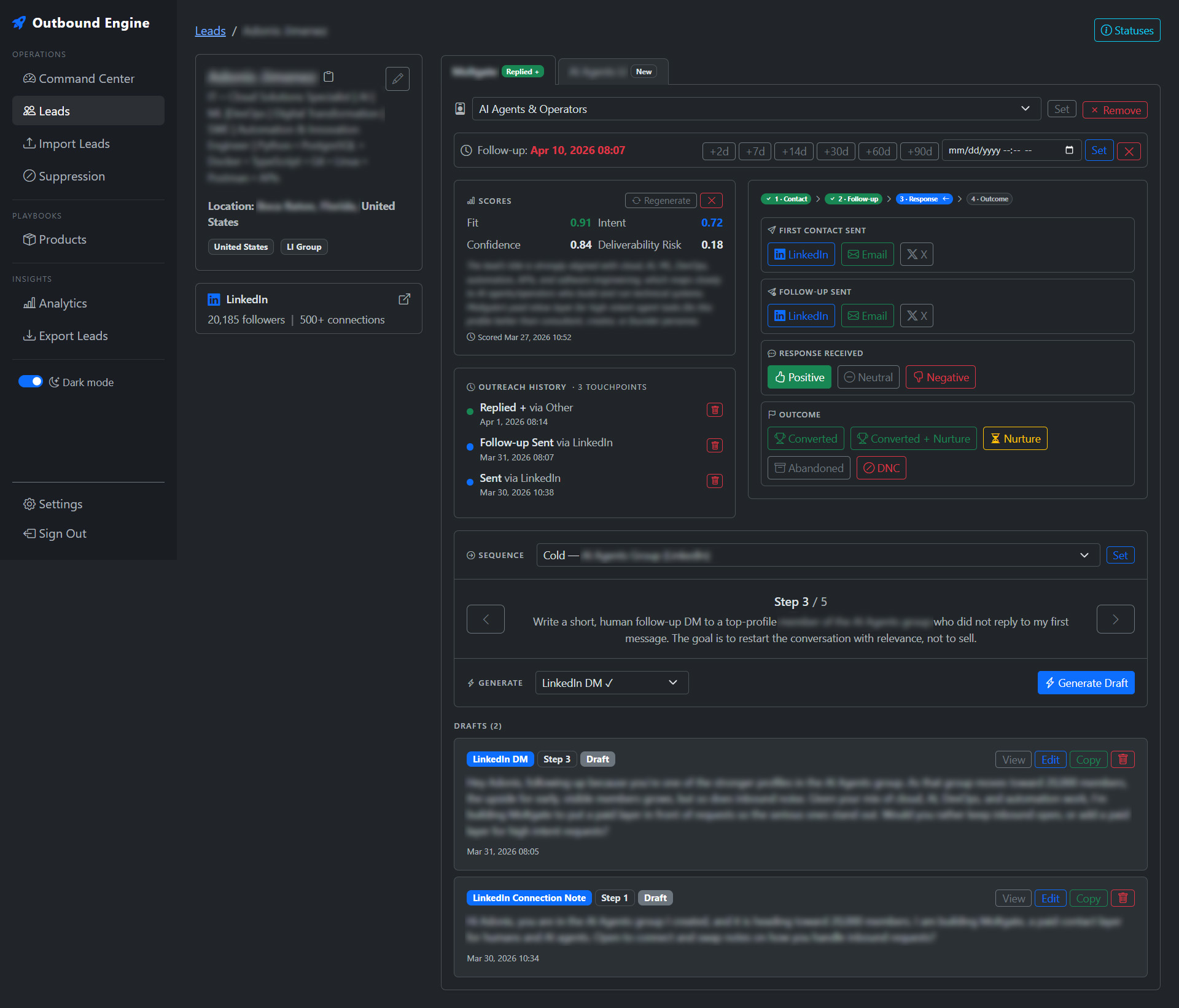
- Draft Generation Pipeline – a multi-stage LLM pipeline with built-in compliance checking.
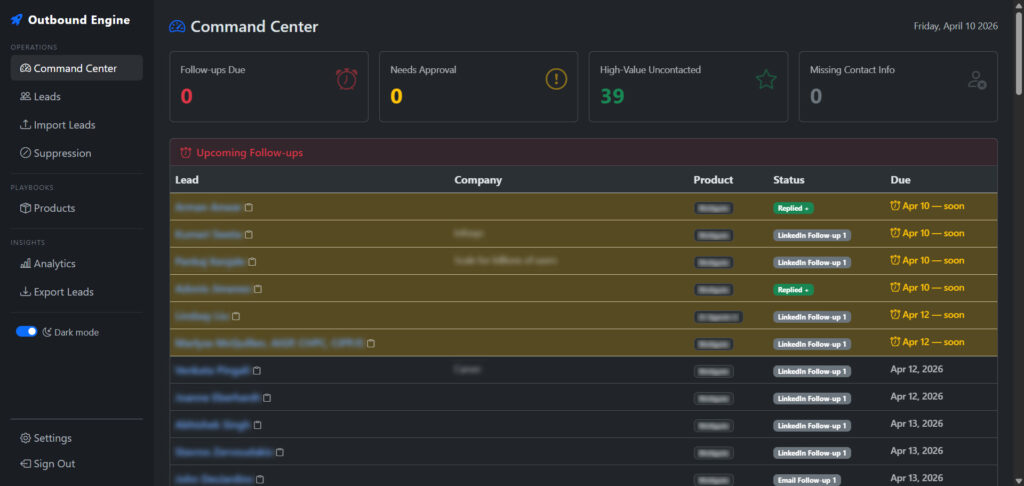
- Command Center – a daily operational dashboard surfacing follow-ups due, approvals needed, and high-value uncontacted leads.
- Analytics – performance tracking by persona, channel, sequence step, and outcome.
Key Technical Decisions
Multi-stage LLM pipeline with a Critic pass
This is the core innovation. Rather than prompting an LLM to “write an outreach email” and hoping for the best, the system uses a structured pipeline:
- A Brief Assembler extracts only verifiable facts from the lead profile and selects relevant playbook assets (proof points, CTAs, persona-specific pitch angles). The output is a structured JSON brief, not prose.
- A Writer generates the channel-specific draft using only the contents of that brief, constrained by channel length limits and tone guidelines.
- A Critic reviews the final draft for hallucinated facts, forbidden claims, guardrail violations, CTA compliance, and length. Drafts that fail are automatically flagged as
NEEDS_APPROVAL.
This architecture means the LLM never has the opportunity to invent facts about a lead. The brief acts as an evidence boundary: if a fact isn’t in the CSV or the playbook, it cannot appear in the draft.
Product Playbook system for reusability
Every product gets its own playbook: a factsheet, a set of personas with tailored pitch cards (pain points, desired outcomes, objection handling), a CTA library, tone guardrails, forbidden claims, and multi-step sequence templates with per-channel variants. This means the entire system is reusable across products. The client launched with one product and can onboard new ones by configuring a playbook, not by rewriting prompts.
Channel-aware generation with enforced length limits
The system supports five outreach channels: Email, LinkedIn DM, LinkedIn connection note, X DM, and X reply. Each has distinct length constraints and tone expectations. LinkedIn connection notes are capped at 200 characters. X messages stay under 280. The generator and critic both enforce these limits, so drafts are copy-paste ready for each platform.
Async processing with Celery
CSV imports, lead scoring, draft generation, and critic checks all run as background tasks. This keeps the UI responsive during bulk operations. Importing and scoring 500 leads doesn’t block the interface. The task pipeline chains generation and critic steps so drafts arrive in a ready-to-review state.
Encrypted API key storage
LLM API keys are stored encrypted at rest, not in plaintext in the database or environment variables alone.
Operational speed as a design constraint
The status management system was designed around a sub-5-second interaction target. One-click actions (“Messaged on LinkedIn”, “Reply +”, “Follow-up sent”) update status, log the outreach event, and optionally set the next follow-up date in a single interaction. Quick follow-up buttons (+2 days, +7 days, +14 days) eliminate date picker friction.
What We Built
Lead Import & Data Pipeline
- CSV upload with interactive column mapping to system fields
- Automatic normalization (email lowercasing, LinkedIn URL cleanup, X handle standardization)
- Multi-strategy deduplication (email, then LinkedIn URL, then X handle, then name + company fallback)
- Global suppression list (email, domain, LinkedIn URL, X handle) with automatic DNC flagging
- Import batch tracking with row counts and metadata
- LLM-powered lead scoring (fit, intent, confidence, deliverability) with optional auto-persona assignment
Product Playbook Configuration
- Structured factsheet editor (one-liner, ICP, differentiators, proof points, CTA library)
- Guardrails configuration (forbidden claims, forbidden words, tone constraints)
- Persona management with pitch cards, pain/outcome/objection libraries, and landing URLs for channel-specific CTAs
- Knowledge base with categorized chunks (home page, pricing, FAQ, proof) used for context in draft generation
- Sequence template builder with per-step objectives, delay scheduling, and channel variants
AI Draft Generation
- Five-channel draft generation (Email, LinkedIn DM, LinkedIn connect note, X DM, X reply)
- Structured brief assembly ensuring evidence-only personalization
- Automated critic/compliance pass checking for hallucination, guardrail violations, and format compliance
- Sequence-step-aware generation (first touch vs. follow-up vs. breakup message)
- Draft versioning and approval workflow with
NEEDS_APPROVALflagging
Command Center & Operational Dashboard
- Daily view: follow-ups due today, drafts needing approval, high-score uncontacted leads, leads missing contact info
- Filterable by product, persona, tags, channel, status, and score thresholds
- One-click status updates with automatic outreach event logging
- Quick follow-up scheduling (+2d / +7d / +14d / custom)
Analytics & Reporting
- Pipeline breakdown by status, persona, channel, and sequence step
- Outreach outcome tracking (sent, replied positive/neutral/negative, converted, bounced)
- KPI dashboard with conversion metrics by product and persona
- CSV export for external reporting
Results
After deployment, the client reported:
- Draft generation time dropped from 5-10 minutes per lead to under 30 seconds, a roughly 15x speedup in the most time-consuming part of the outbound workflow.
- Zero hallucination incidents in production outreach. The brief-assembler-plus-critic architecture eliminated the category of error that had previously required line-by-line review of every AI-generated message.
- Operational overhead for status management fell below 5 seconds per lead, down from the scattered spreadsheet-and-memory system that preceded it.
- Full pipeline visibility. For the first time, the client could see at a glance how many leads were at each stage, which follow-ups were overdue, and which channels were converting, enabling data-driven decisions about where to focus effort.
Technical Summary
| Component | Technology |
|---|---|
| Backend framework | Python – Django |
| Async task processing | Celery |
| LLM integration | OpenAI API |
| Database | SQLite / PostgreSQL |
| Authentication | django-allauth |
| Testing | pytest + pytest-django |
Why This Project Matters
Outbound Engine demonstrates a pattern we see repeatedly: the gap between “use ChatGPT for X” and “build a reliable AI system for X” is larger than most teams expect. The raw LLM capability, generating a plausible-sounding outreach email, is table stakes. The hard problems are structural:
- How do you prevent hallucination when the LLM’s job is personalization?
- How do you enforce brand and compliance rules across thousands of generated messages?
- How do you make the system reusable across products without prompt engineering for each one?
- How do you integrate AI generation into an operational workflow that humans actually use at speed?
These are the problems we solve. If your team is sitting on an AI use case that needs to move from “demo” to “production system,” we’d like to talk.